
A 3D-Aware and Controllable Framework for Cinematic Text-to-Video Generation
In this work, we present CineMaster, a novel framework for 3D-aware and controllable text-to-video generation. Our goal is to empower users with comparable controllability as professional film directors: precise placement of objects within the scene, flexible manipulation of both objects and camera in 3D space, and intuitive layout control over the rendered frames. To achieve this, CineMaster operates in two stages. In the first stage, we design an interactive workflow that allows users to intuitively construct 3D-aware conditional signals by positioning object bounding boxes and defining camera movements within the 3D space. In the second stage, these control signals—comprising rendered depth maps, camera trajectories and object class labels—serve as the guidance for a text-to-video diffusion model, ensuring to generate the user-intended video content. Furthermore, to overcome the scarcity of in-the-wild datasets with 3D box and camera pose annotations, we carefully establish an automated data annotation pipeline that extracts 3D bounding boxes and camera trajectories as control signals from large-scale video data. Extensive qualitative and quantitative experiments demonstrate that CineMaster significantly outperforms existing methods and implements prominent 3D-aware text-to-video generation.
|
A man flies to the moon.
|
A golden boat flies between clouds.
|
A dolphin flies to the sun.
|
|---|---|---|
|
A McLaren is parked on a road, a person walks in front of the camera.
|
A man is walking towards the boat at the seaside.
|
A man is walking on the clouds with a moon in the background.
|
|
A car passes another car from behind.
|
A panda is driving a motorcycle in a city.
|
A cat jumps down from the table.
|
|
A green magic orb revolves around the wizard.
|
The hot air balloon is circling above a tower.
|
A bird circles around a man.
|
|---|---|---|
|
Two whales swim towards each other.
|
A fireball descends from the sky and strikes towards a bear.
|
A bus is traveling on a countryside winding road with lots of flowers along the side of the road.
|
|
A crystal ball skips across the lake surface.
|
A person is riding a tiger in a forest.
|
The tortoise crawls while the hare hops and bounces.
|
|
A tiger is lying on a block of ice.
|
A ginger cat lounges on a rock with a sea in the background.
|
A rabbit sits on a table with a temple in the background.
|
|---|---|---|
|
A woman stands by the seaside, admiring the beautiful sunset glow.
|
A man is holding a bottle of wine.
|
A lighthouse stands on a calm sea with the colorful aurora in the background.
|
We compare CineMaster with existing SOTA methods for three different feature comparisons: moving object & static camera, static object & moving camera and moving object & moving camera. In comparison, CineMaster could better control object motion and camera motion separately or jointly to generate diverse user-intended scenes.
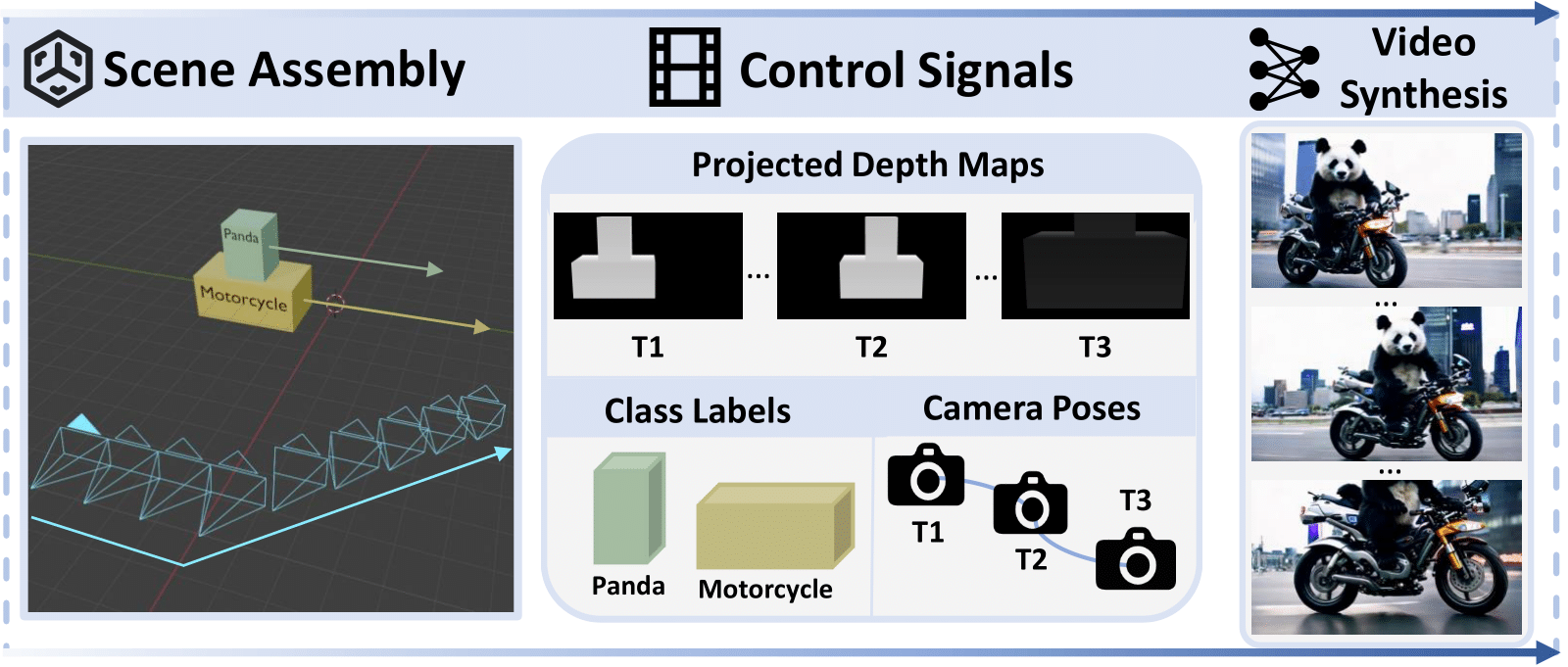
We present CineMaster, a framework that enables users to manipulate objects and camera in the 3D space for text-to-video generation. CineMaster consists of two stages. First, we present an interactive workflow that allows users to intuitively manipulate the objects and camera in a 3D-native manner. Then the control signals are rendered from the 3D engine and fed into a text-to-video diffusion model, guiding the generation of user-intended video content.
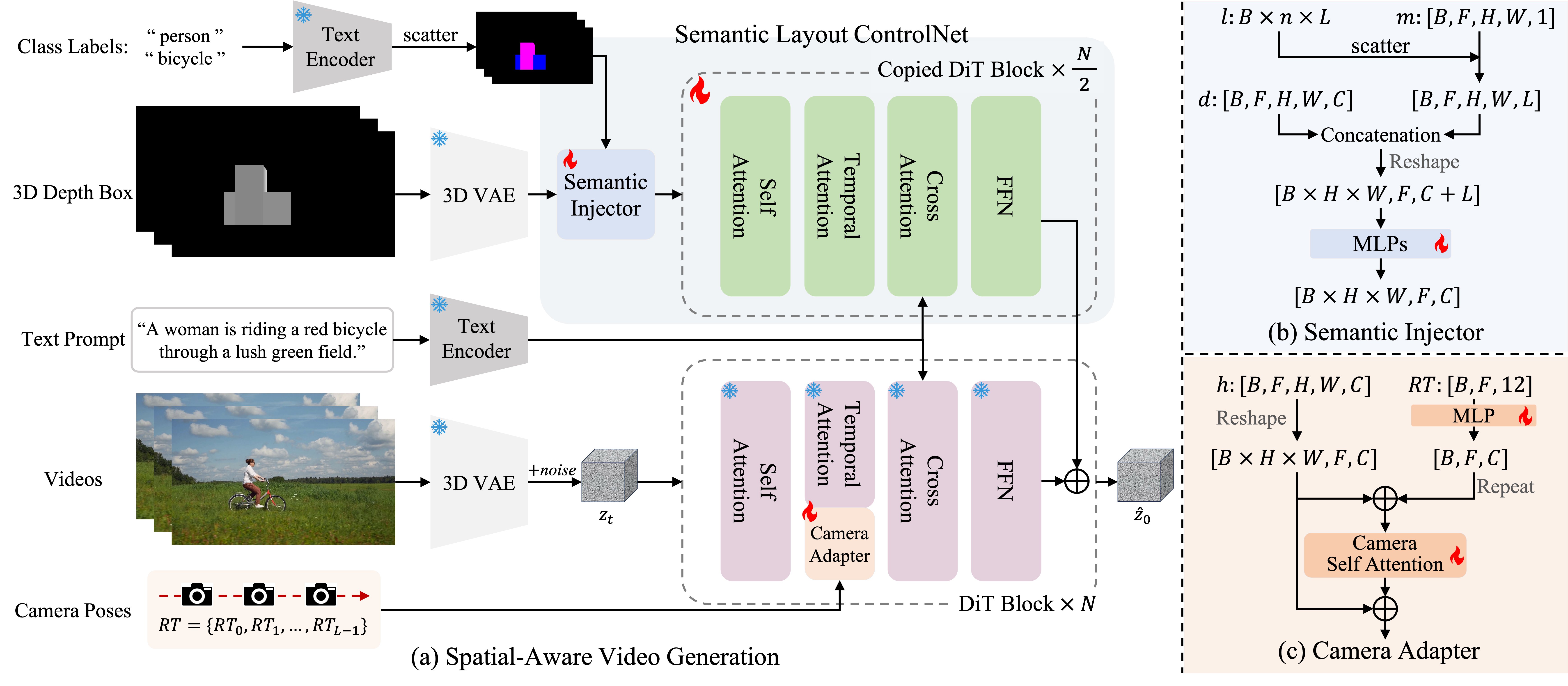
Overview of the network architecture. We design a Semantic Layout ControlNet which consists of a semantic injector and a DiT-based ControlNet. Semantic injector fuses the 3D spatial layout and class label conditions. The DiT-based ControlNet further represents the fused features and adds to the hidden states of the base model. Meanwhile, we inject the camera trajectories by the camera adapter to achieve joint control over object motion and camera motion.
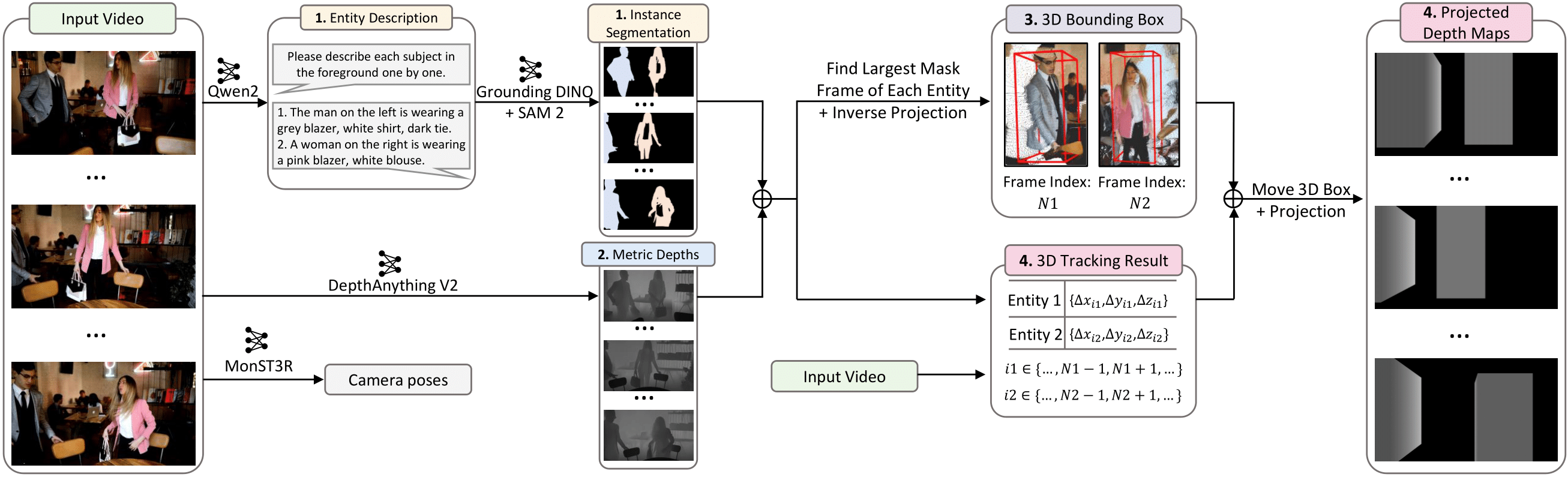
Dataset Labeling Pipeline. We propose a data labeling pipeline to extract 3D bounding boxes, class labels and camera poses from videos. Our pipeline consists of four steps: 1) Instance Segmentation: Obtain instance segmentation results from the foreground in videos. 2) Depth Estimation: Produce metric depth maps using DepthAnything V2. 3) 3D Point Cloud and Box Calculation: Identify the frame with the largest mask for each entity and compute the 3D point cloud of each entity through inverse projection. Then, use the minimum volume method to calculate the 3D bounding box for each entity. 4) Entity Tracking and 3D Box Adjustment: Access the point tracking results of each entity and calculate the 3D bounding boxes for each frame. Finally, project the entire 3D scene into depth maps.
Our project page is borrowed from DreamBooth.